
The PARSE Framework: Make Pakistani Sites Visible to AI Agents
Last updated: June 2026. By Abdul Rehman, Technical SEO Lead at WeProms Digital.
Start here. Before a Pakistani brand worries about ranking, it has to solve a simpler problem: can an AI agent actually read the page at all? The PARSE framework breaks AI invisibility into five steps: P for Parseable HTML, A for Accessible markup, R for Reachable crawlers, S for Structured data, and E for Entity clarity. Each step maps one technical layer that decides whether ChatGPT, Perplexity, or Google AI Mode can extract your product names, PKR prices, and category structure from the page.
Picture this. A shopper in Lahore types “best affordable air cooler under PKR 40,000 in Pakistan” into ChatGPT. The engine does not click through ten blue links. It reads the pages its crawler already fetched, extracts the ones it could parse, and synthesizes an answer citing two or three brands. If your store rendered its price and specs through a JavaScript widget the AI crawler never executed, you are simply not in the answer. There is no error message, no penalty, no notification. The crawler just moved on to a competitor it could read.
This matters more in Pakistan than almost anywhere else in the region. PTA data places smartphone penetration above 66% nationwide in early 2026, with Lahore alone adding roughly three million new mobile internet users, which means the next wave of Pakistani shoppers will research purchases on devices and through interfaces that depend entirely on machine-readable pages. A site built for human eyes but not for AI agents is invisible to that entire audience.
P — Parseable HTML: Does your store render critical text without JavaScript?
Parseable HTML means the most important text on the page, product names, prices, specs, and headings, exists in the raw HTML that an AI crawler receives on its first request. When that text only appears after JavaScript runs, many AI crawlers never see it, which means your offer effectively does not exist for the citation.
Search Engine Journal reports that the accessibility tree, the structured map of a page that AI agents use to read content, is breaking across large parts of the web. The accessibility tree is built from semantic HTML elements like <header>, <main>, <article>, and <h1> through <h6> headings. When a Pakistani Shopify or WordPress theme wraps product titles in custom JavaScript components without a semantic fallback, the accessibility tree collapses for that section, and the AI crawler extracts nothing useful.
The tradeoff is real. JavaScript-heavy themes deliver slick animations and dynamic filtering that convert human visitors, but they trade away machine readability. The fix is server-side rendering or pre-rendering the critical text, so product names and PKR prices land in the initial HTML payload even if the interactive layer loads later. A page that serves its core content as static HTML keeps both the human experience and the AI citation.
The actionable step is narrow. Open your store in a browser, disable JavaScript, and reload. If the product name, price, and buy button text disappear, that content is invisible to a large share of AI crawlers, which means it is invisible to AI search.
A — Accessible markup: Can an AI crawler label your images and forms?
Book a free strategy call - we'll audit your current setup and identify the highest-impact fixes.
Accessible markup means every image, form field, and interactive element carries a text label that describes its purpose, written for screen readers and, by extension, for AI agents. The W3C Web Accessibility Initiative defines accessibility as a set of shared components, and AI crawlers happen to consume the exact same labels that screen readers do.
The connection is not coincidence. AI engines that synthesize answers re-use the accessibility tree as their primary reading surface, because it is the cleanest structured representation of a page. An unlabeled product image on a Karachi apparel store is a blank tile to the AI; the same image with descriptive alt text becomes a citable data point. Forms without aria-label attributes are unreadable buttons; forms with them become clear actions the engine can describe to a shopper.

The practical test is a screen-reader pass or an automated accessibility scan. Pakistani stores that fix missing alt text, add form labels, and label icon buttons typically recover meaningful citation surface within weeks, because they are repairing the exact layer AI engines read first. Accessibility work and GEO work are the same work, viewed from two angles.
R — Reachable crawlers: Have you opened the door to AI bots in robots.txt?
Reachable crawlers means your robots.txt file and server firewall explicitly allow the AI bots that power ChatGPT, Perplexity, and Google AI Mode to fetch your pages. Many Pakistani stores block these bots by accident, through inherited WordPress security plugins or default Cloudflare rules that treat unknown user agents as threats.
The Google Search Central documentation on robots.txt explains that disallowed crawlers receive no content, which is the binary nature of the problem: a crawler is either allowed to read the page or it is not. There is no partial visibility. A store that disallows GPTBot, ClaudeBot, or PerplexityBot in robots.txt has opted out of citation in those engines entirely, usually without realizing it.
A useful analogy is a delivery rider in a Lahore neighborhood with no street numbers. The rider can carry the package, but if the gate is locked and there is no nameplate, the order fails. AI crawlers are the same. They will fetch and read your page, but only if your robots.txt leaves the gate open and your firewall does not challenge them at the door.
The actionable step is to open robots.txt, confirm that the major AI crawlers are not disallowed, and whitelist the specific user agents your customers actually use to research purchases. This single fix has recovered more AI citation surface for Pakistani stores than any content change in the teams we advise.
S — Structured data: Does schema markup tell AI engines what your prices and products are?
Structured data means schema.org markup, usually delivered as JSON-LD, that explicitly tells machines what each piece of content is: a product, a price, a review, a local business, or a frequently asked question. Without it, the AI engine guesses; with it, the AI engine knows. The difference between guessing and knowing is the difference between a citation and silence.
The schema.org vocabulary and the Google Search Central structured data guide provide the formats AI engines increasingly rely on, because structured data removes ambiguity. A Pakistani electronics store that marks up its products with Product, Offer, and priceCurrency: PKR gives ChatGPT an unambiguous signal that it sells a specific item at a specific price, which makes it a strong candidate for a price-comparison answer.
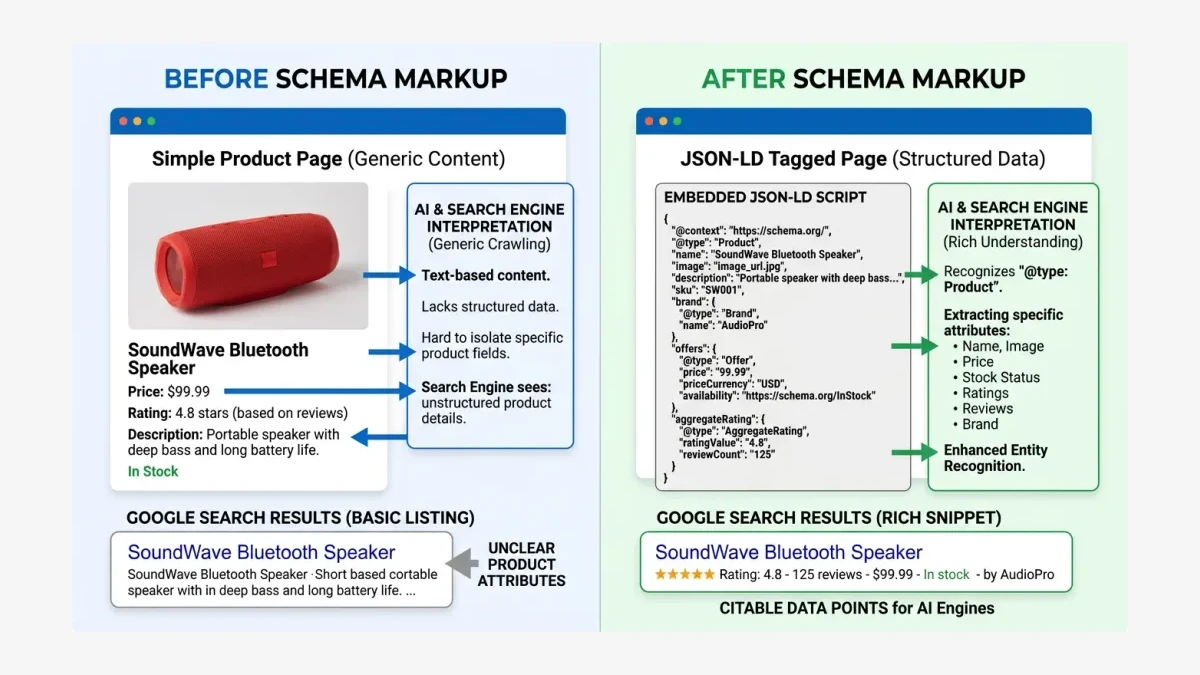
The payoff compounds. Product schema feeds AI price comparisons, FAQ schema feeds AI answer extraction, and LocalBusiness schema feeds location-based recommendations, which matters enormously for Pakistani service businesses competing for “near me” queries in Karachi, Lahore, and Islamabad. One consistent JSON-LD layer unlocks citation across multiple answer types.
E — Entity clarity: Can an AI engine connect your brand to the right knowledge graph node?
How we helped a Pakistani business achieve measurable results.
Entity clarity means your brand, products, and locations are named consistently and connected to recognized identifiers, so an AI engine can place you in its knowledge graph rather than treating you as an unknown string of text. Entities, distinct named things like a brand, a city, or a product category, are the currency AI engines use to decide who to cite.
An AI engine does not understand your brand by reading one page. It builds a picture by connecting mentions across your site, your Google Business Profile, press coverage, and structured identifiers like a Wikidata entry. Google Business Profiles now offer a Message Button With AI Agent, which signals how tightly Google is weaving business identity into AI interactions. A Pakistani brand with inconsistent name, address, and category data across Daraz, its own site, and its Google Business Profile fragments its entity, which means the AI engine never assembles a confident enough picture to cite it.
The actionable step is consistency. Use exactly one brand name, one canonical address, and one category description everywhere, link your pages with internal anchors that name the entity, and claim or correct your Google Business Profile, Wikidata, and major directory listings. Entity clarity is slow work, but it is the layer that decides whether an AI engine recommends you by name or recommends a generic competitor instead.
At WeProms Digital, we apply the PARSE framework through technical SEO audits, schema markup implementation, and generative engine optimization that make Pakistani brands readable to AI agents. If ChatGPT and Perplexity are not citing your store, request a PARSE audit by emailing hello@weproms.com or messaging WhatsApp at +92 300 0133399. The team will crawl your site the way an AI agent does, map every layer that is breaking, and sequence the fixes that restore citation.
Read next: Technical SEO for AI search visibility in Pakistan and Why Google AI Mode never cites your Pakistani business.
Key Takeaways
- PARSE is sequential. Parseable HTML comes first, because nothing downstream matters if the crawler cannot read the page on its first request.
- Accessibility work is GEO work. The labels that help screen readers are the exact labels AI agents read, so accessible markup doubles as citation surface.
- Robots.txt is binary. An AI crawler is either allowed or blocked; default security plugins often block GPTBot and ClaudeBot without the owner knowing.
- Schema removes guesswork. Product and Offer markup with
priceCurrency: PKRgives AI engines unambiguous price data they can cite in comparisons. - Entity clarity compounds slowly. Consistent name, address, and category data across your site, Google Business Profile, and directories is what lets an AI engine cite you by name.
Frequently Asked Questions
What is the accessibility tree and why does it matter for Pakistani websites?
The accessibility tree is the structured map of a page that AI agents and screen readers use to read content, built from semantic HTML elements like headings, landmarks, and labels. It matters for Pakistani websites because AI engines such as ChatGPT and Perplexity use the same tree to decide what to cite, so a broken tree means your product names and PKR prices never reach the answer.
How much does a PARSE technical SEO audit cost with WeProms?
A PARSE audit is scoped by page count and CMS complexity, with pricing in PKR and no minimum spend. The audit crawls the site the way an AI agent does, maps the five PARSE layers, and delivers a fix sequence. Request a quote through weproms.com/contact-us and the team will scope it against your actual store.
Should I allow GPTBot and ClaudeBot in my robots.txt?
Yes, if you want AI engines to be able to cite your products. Blocking these bots in robots.txt or via a firewall plugin opts you out of citation in ChatGPT and Claude entirely. The tradeoff is a small crawl-cost increase, which is negligible compared with the discovery value of being recommended inside an AI answer.
Does the PARSE framework work for Urdu-language Pakistani sites?
Yes. Parseable HTML, accessible markup, structured data, and entity clarity are language-agnostic, and schema.org supports multilingual content through the inLanguage property. Urdu-language product pages benefit from the same five layers, and consistent entity naming helps AI engines connect Urdu and English mentions of the same brand.
How long until AI engines start citing my site after a PARSE fix?
Citation recovery usually appears within two to six weeks after the technical fixes are live, because AI engines re-crawl and re-index on their own schedules. Schema markup and robots.txt fixes often surface fastest, while entity clarity work compounds over months as the knowledge graph updates across engines.
About WeProms Digital
WeProms Digital is Pakistan’s leading technical SEO and GEO agency, headquartered in Lahore and serving Pakistani SMEs, ecommerce brands, and B2B teams across Lahore, Karachi, Islamabad, Rawalpindi, Faisalabad, and Multan.
The team specializes in technical SEO audits, schema markup implementation, and AI-readability optimization, with a track record of making Pakistani stores parseable, reachable, and citable across ChatGPT, Perplexity, and Google AI Mode.
Get in touch: hello@weproms.com · WhatsApp +92 300 0133399 · weproms.com/contact-us
Sources & References
- Schema.org — Vocabulary for Structured Data on the Web — accessed June 2026
- Google Search Central — Manage Your Crawling and Indexing with robots.txt — accessed June 2026
- Google Search Central — Introduction to Structured Data — accessed June 2026
- W3C Web Accessibility Initiative — Components of Web Accessibility — accessed June 2026
- MDN Web Docs — Accessibility Tree — accessed June 2026
- Web Development Lahore — The Importance of Mobile-First Web Design in Pakistan (PTA data) — 2026
- Search Engine Roundtable — Google Business Profiles Adds Message Button With AI Agent — 2026
Additional reading from industry feeds:



