
The Cloudflare Update That Can De-Index Pakistani Sites on September 15
By Abdul Rehman — published July 5, 2026. Last updated July 2026.
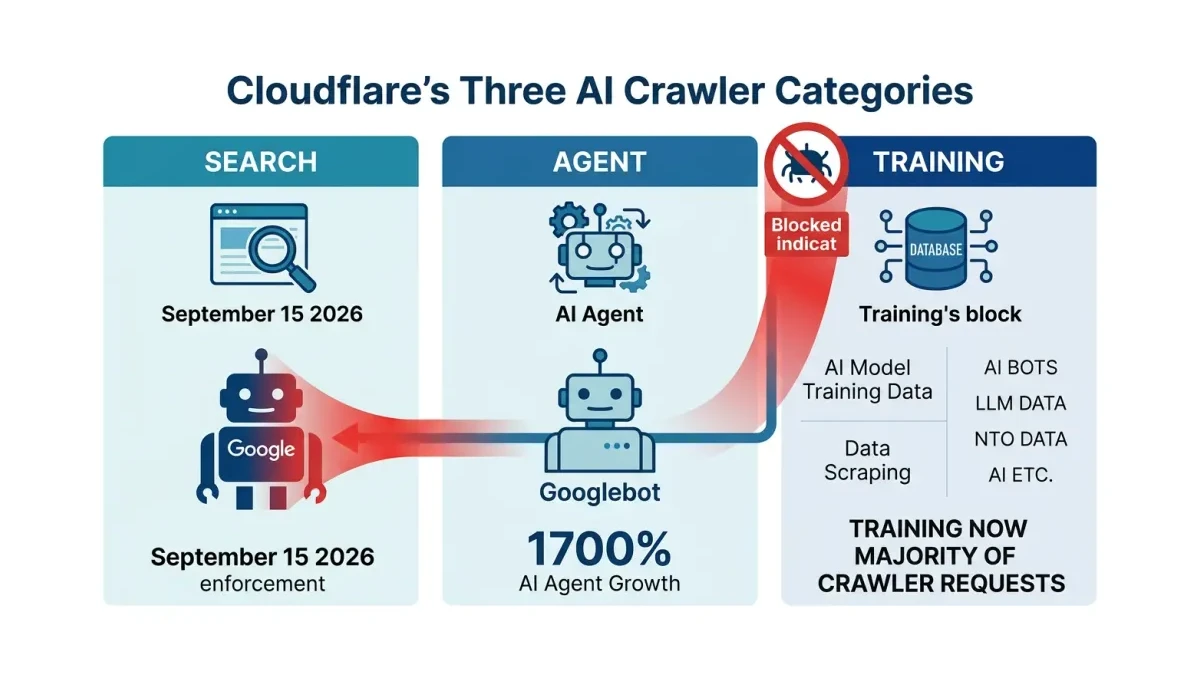
On September 15, 2026, Cloudflare flips a default that blocks AI training and agent crawlers on ad-supported pages. Because Googlebot, Applebot, and Bingbot crawl for both search and training at once, blocking the Training category can quietly block the very bots that keep your Pakistani store in Google Search. A 15-minute settings check before that date protects weeks of organic revenue.
If you run a Pakistani ecommerce site behind Cloudflare — and a lot of stores on Shopify, WooCommerce, Daraz-connected storefronts, and custom builds do — a configuration that flips on September 15, 2026 can pull your pages out of Google’s index without sending a single warning. The change is well-intentioned. Cloudflare wants to give publishers control over who trains AI models on their content. The tradeoff is that the same switch can also cut off the crawlers that fill your sales funnel. This walkthrough shows the exact sequence to keep your Google rankings intact.
Picture this. Your Karachi apparel store ranks on page one for “stitched lawn suits online.” On September 16, impressions in Google Search Console drop to zero across every category page. No manual action, no penalty email, no hack. Cloudflare started blocking the Training category by default, and because Googlebot trains models as well as indexes pages, Googlebot got blocked too. The fix is not a lawyer or a reconsideration request. The fix is a settings review you can finish before lunch.
Blocking the Training category is like telling your building’s security guard to stop scrap dealers from entering — but the guard cannot tell a scrap dealer from the Daewoo courier carrying your parcels, so he blocks both, and your deliveries stop for a week before anyone notices.
First, understand what Cloudflare changed on July 1
Cloudflare announced its new AI traffic controls on July 1, 2026, replacing the old single “Block AI Bots” toggle with three separate switches, as TechCrunch reported. The three categories are Search (crawlers that index your content so they can refer users back to you), Agent (real-time bots acting on a human’s behalf, like ChatGPT-User or Gemini driving a browser), and Training (crawlers that permanently absorb your content into a model).
Under the new model, Search crawlers stay allowed by default because they drive referral traffic back to you. Training and Agent crawlers get blocked by default on ad-supported pages. AI training now accounts for the majority of crawler requests on Cloudflare’s network, up from roughly 20% in spring 2025, and daily AI agent requests grew more than 1,700% year-over-year. Cloudflare’s network is large enough to move the whole web with one default change — it blocked more than 20 million DDoS attacks in Q1 2025 alone, according to StationX. So what? The volume of bot traffic is now large enough that default-deny has become Cloudflare’s safest position — but safe for the network is not always safe for your Google visibility.
Then, find out which Cloudflare plan and tier you are on
Book a free strategy call - we'll audit your current setup and identify the highest-impact fixes.
Log in to your Cloudflare dashboard and open the account overview. The September 15 default applies to three groups: new Cloudflare customers, new domains added by existing customers, and existing free-tier users who have never customized their crawler settings, according to the AI/TLDR release breakdown. If you are on a paid Pro, Business, or Enterprise plan and you have already touched your bot settings, your current rules stay as-is for now.
The actionable step: screenshot your current plan tier and your current Security Settings tab today. That screenshot is your before-state. Without it, you cannot prove what changed if traffic drops on September 16, and you will waste days guessing.
Next, check whether your pages count as ad-supported
The default block on Training and Agent applies specifically to pages that display ads. If your Pakistani store runs Google AdSense, Mediavine, affiliate display banners, or any third-party ad network on its product or blog pages, those pages fall under the ad-supported definition. Pure ecommerce checkout pages with no ads are treated differently.
Be honest about this check. Many store owners assume “I don’t run ads” because they do not buy Google Ads, but display ad networks on a blog section still count. As Novaknown noted, what changes on September 15 is a default setting, not a universal toll — but defaults are what most free-tier sites inherit without realizing it. The tradeoff is that ad-supported pages get the stricter default precisely because Cloudflare is pushing AI companies toward its Pay Per Crawl and Pay Per Use monetization, as described on the Cloudflare blog.
After that, separate Search from Training in your dashboard
This is the step where most de-indexings happen. Open the Security Settings tab on your zone and find the three new switches: Search, Agent, Training. Confirm Search is set to Allow. Then decide Training and Agent deliberately rather than leaving them on the incoming default.
| Setting | Old “Block AI Bots” toggle | New three-switch model | Risk for Pakistani stores |
|---|---|---|---|
| Search crawlers (Googlebot indexing) | Often blocked by accident | Allowed by default | Low if left on Allow |
| Training crawlers | Blocked with everything else | Blocked by default on ad pages | Medium — see next section |
| Agent crawlers | Blocked with everything else | Blocked by default on ad pages | Low for most stores |
| Multi-purpose bots (Googlebot, Applebot, Bingbot) | One rule for all | Blocked by strictest behavior | High if Training is blocked |
The danger row is the last one. Cloudflare now applies the strictest rule across all of a crawler’s behaviors. Googlebot indexes for Search and also trains Google’s models, so if you block Training, Googlebot gets blocked too — not because you wanted it gone, but because the rule follows the bot, not the job.
At this point, verify Googlebot can still reach your site
How we helped a Pakistani business achieve measurable results.
Do not trust the dashboard. Test the actual crawl path. Open Google Search Console, go to URL Inspection, and run a live test on your homepage and one product page. The live fetch should return a 200 status and show rendered HTML. Then check the Coverage report over the following week for any sudden drop in indexed pages, which is the earliest signal that Googlebot has been blocked at the network edge.
A network-level block is harder to bypass than a robots.txt advisory, which means the standard “Google can still read my robots.txt” comfort no longer applies. The actionable step: set a calendar reminder for September 16 and September 23 to compare indexed page counts before and after the switch. A drop of more than 5% in a week with no content change is a red flag.
Once you’ve confirmed, set the content-use signal in robots.txt
Cloudflare’s managed robots.txt now emits a content-use signal by default, with three values: use=immediate (store nothing), use=reference (index, excerpt, and link back — the new default), and use=full (summarize and reproduce). These are stated preferences, not hard blocks, as SEO consultant Pedro Dias noted on LinkedIn, which means a signal only matters for crawlers that choose to honor it.
For most Pakistani store owners, leaving the default at use=reference is the right call: it lets AI search engines cite your product pages and link back, which supports AI-driven discovery, without giving away full reproduction rights. The tradeoff is between maximum protection (use=immediate, which reduces AI citations) and maximum reach (use=full, which lets models reproduce your content). Reference is the middle path.
From here, put a monthly monitoring check on the calendar
Defaults change. Cloudflare already shifted its position once between spring 2025 and July 2026, and the September 15 enforcement is the second wave, with more likely as Pay Per Use matures. A one-time fix protects you today; a monthly check protects you across the next default flip.
The outcome of this walkthrough is a verified crawl path that survives September 15. You will know your plan tier, your ad-supported status, your three switch positions, and your Googlebot reachability — all documented in one screenshot folder. That folder is what you hand to a developer or an agency if traffic ever drops, instead of starting from a blank diagnosis.

Pakistan counts more than 154 million mobile subscribers, per Statista, which makes Google search visibility a mobile-first revenue line that a misconfigured crawler block can silence overnight. Cloudflare’s CEO, Matthew Prince, has warned that AI agents could “destroy small businesses” by concentrating customer acquisition in a few platforms. His company’s defaults are a defensive response to that threat, but a defense that accidentally blocks Googlebot hurts the small Pakistani business it claims to protect. The cost of inaction is silent: pages drop from Google’s index, organic revenue falls, and the cause hides inside a dashboard the owner never opens.
Read next: For the strategic decision of whether to block, allow, or monetize AI crawlers, read Block, Allow, or Monetize AI Crawlers on Your Pakistani Website. For the broader crawler governance setup, see our guide to AI crawler access and bot governance. For what visibility loss looks like once it surfaces in your traffic numbers, read the AI Overview click-loss operator breakdown.
At WeProms Digital, we run Cloudflare crawler audits as part of our AI crawler access and bot governance service and our technical SEO work. As Pakistan’s leading technical SEO agency, we verify Googlebot reachability before and after every default change so your pages stay indexed. Book a pre-September-15 audit at weproms.com/contact-us, email hello@weproms.com, or message WhatsApp +92 300 0133399.
Frequently Asked Questions
Will the Cloudflare September 15 update remove my Pakistani site from Google?
Not by itself, and not if you act before the date. The default blocks Training and Agent crawlers on ad-supported pages. Because Googlebot also trains models, blocking Training can block Googlebot too unless you confirm Search is set to Allow and verify the live crawl path in Google Search Console.
I am on Cloudflare’s free plan. Do I need to do anything?
Yes. Existing free-tier users who have never customized crawler settings are exactly the group the September 15 default applies to. Open the Security Settings tab, confirm Search is Allow, and screenshot the configuration before the date so you can compare if traffic drops.
How do I check if Googlebot is blocked by Cloudflare?
Run a URL Inspection live test in Google Search Console on your homepage and a product page. A successful fetch returns a 200 status with rendered HTML. Then watch the Coverage report for a sudden drop in indexed pages within the first two weeks after September 15.
Does WeProms manage Cloudflare crawler settings for Pakistani stores?
Yes. Our AI crawler governance service audits your plan tier, ad-supported status, the three crawler switches, and the content-use signal, then verifies Googlebot reachability and sets a monthly monitoring check. Request a fixed quote at weproms.com/contact-us.
Should I block AI training crawlers to protect my content?
It depends on whether AI-driven discovery matters to your store. Leaving the content-use signal at use=reference lets AI search engines cite and link back to you, which supports visibility. Blocking everything with use=immediate protects content but also reduces AI citations and, misconfigured, can reduce Google indexing.
Sources & References
- TechCrunch — Cloudflare’s New Policy Pushes AI Companies to Pay for Publishers’ Content — July 2026
- AI/TLDR — Cloudflare AI Traffic Controls (Search, Agent, Training) — July 2026
- Cloudflare Blog — Introducing Pay Per Crawl — 2025
- Pedro Dias (LinkedIn) — Cloudflare Reshapes AI Crawler Controls — July 2026
- India Today — Cloudflare CEO Warns AI Will Destroy Small Businesses — June 2026
- StationX — Cloudflare DDoS and Bot Traffic Statistics — 2025
- Novaknown — Cloudflare Blocks AI Crawlers by Default — July 2026
- Statista — Pakistan Digital Connectivity Outlook — 2026
Additional reading from industry feeds:



